
搜索
搜索

有媒体征引知情东说念主士显现的音讯报说念称开云kaiyun.com,各人AI行业无比期待的英伟达(NVDA.US)下一代AI GPU架构——“Rubin”架构,可能将提前六个月,即2025年下半年认真发布。天然Blackwell架构AI GPU仍未大范围发货且被爆出头临散热问题,但英伟达似乎坚韧加速其AI GPU发展阶梯图,濒临AMD、亚马逊以及博通等AI芯片竞争敌手发起的横蛮攻势,这家“绿色巨东说念主”试图强化它在数据中心AI芯片市集的都备主导地位。英伟达现时在该市集号称“操纵”,占据80%-90%份额。
尽管 Blackwell 架构AI GPU可能来岁第一季度智力在台积电、鸿海、纬颖以及纬创等迢遥中枢供应商都心合力之下达成大范围量产,然而跟着谷歌、亚马逊等云巨头自研AI芯片波浪席卷而来,英伟达面前比以往任何时候都愈加致力于于在数据中心AI芯片市鸠集保抓主导地位。对于英伟达推动们来说,他们也需要新的催化剂推动英伟达股价向200好意思元发起冲击。
包括OpenAI以及微软在内的迢遥AI行业领军者,以及摩根士丹利等华尔街投行们照旧驱动酌量英伟达下一代架构Rubin的性能将何如强壮。一些产业链分析东说念主士合计依托共同封装光学(CPO)工夫以及HBM4,加之台积电3nm以及下一代CoWoS先进封装所打造的Rubin架构AI GPU号称“史无先例的性能”,有可能开启AI算力全新纪元,竞争敌手们可能需要消费数年时期来进行追逐。
字据产业链知情东说念主士显现的音讯,英伟达Rubin架构的居品线原定于2026年上半年推出,现已条目供应链开启提前测试使命,力图提前至2025年下半年认真推出。由于OpenAI、Anthropic、xAI以及Meta等东说念主工智能、云测度以及互联网大厂们对于AI测验/推理算力简直无终点的“井喷式需求”,迫使英伟达以更快速率推出性能更高、存储容量更迢遥、推理恶果更强壮且愈加节能的下一代AI GPU的研发程度。这家绿色巨东说念主试图加速不同AI GPU架构之间的更新节拍。
天然英伟达官方未进行恢复,然而从存储芯片制造巨头SK海力士(SK Hynix)上月初显现的可能提前坐褥委用HBM4的音讯来看,对于Rubin音讯的确实性荒谬高。HBM通过3D堆叠存储工夫,将堆叠的多个DRAM芯片全面聚会在一都,通过轻微的Through-Silicon Vias(TSVs)进行数据传输,从而达成高速高带宽的数据传输,使得AI大模子能够24小时接续绝地更高效地运行。
据了解,SK集团董事长崔泰源在11月初接受采访时暗意,英伟达首席扩充官黄仁勋条目SK海力士提前六个月推出其下一代高带宽存储居品HBM4。当作英伟达H100/H200以及近期驱动坐褥的Blackwell AI GPU的最中枢HBM存储系统供应商,SK海力士一直在引颈各人存储芯片产能竞赛,以满足英伟达、AMD以及谷歌等大客户们满足对HBM存储系统的爆炸性需求以偏激他企业对于数据中心SSD等企业级存储居品的需求,这些存储级的芯片居品对于处理海量数据以测验出愈发强壮的东说念主工智能大模子以及需求剧增的云霄AI推理算力而言号称中枢硬件。
在对于Rubin的最新音讯出炉之前,英伟达面前正处于“一年一代际”的AI GPU架构更新节拍中,这意味着该公司每年都会发布新一代架构的数据中心AI GPU居品,这等于为什么Ampere、Hopper和Blackwell架构之间都有长达一年的间隔;联系词,对于Rubin,这种情况可能澈底编削。
知情东说念主士并未说起英伟达为何要提前推出Rubin的具体原因,仅仅将其归类为一项买卖举措。联系词,淌若咱们从供应链角度来看,Rubin揣度将秉承台积电的3nm工艺,以及存储领域具有划时间意旨的HBM4,加上可能是各人首个取舍CPO+硅晶圆封装的数据中心级别AI芯片,这些最关键的中枢按序要么照旧驱动准备——比如台积电3nm准备就绪、HBM4可能照旧处于测试按序,要么已顺服能够达成量产,比如CPO封装。因此,鉴于英伟达可能照旧为Rubin配备了通盘“器具”,黄仁勋可能合计在2026年发布Rubin不太合乎。
字据英伟达在GTC清晰的居品阶梯,Blackwell升级版——“Blackwell Ultra”居品线,即“B300”系列的初次亮相,英伟达方案在2025年中期发布该系列。因此,咱们可能将看到Blackwell Ultra与Rubin发布的时期点荒谬围聚。面前发布计策尚不解确,但Wccftech以及The Verge的一些专科东说念主士暗意,英伟达可能将重心放在Rubin架构,将B300系列视为过渡居品。按照英伟达旧例,揣度该公司很快会将发布更多更新,可能是在2025年外洋消费电子展(CES)前后。
Blackwell照旧荒谬强壮! 但Rubin,或将开启AI算力新纪元
Blackwell架构AI GPU系列居品,毫无疑问是现时AI算力基础设施领域的“性能天花板”。在Blackwell出炉前,Hopper也一度被视为算力天花板,而在CPO以及3nm、比拟于HBM3E性能大幅增强的HBM4,加之下一代CoWoS加抓下,暂不接头Rubin自身的基础架构升级,Rubin芯片性能可能照旧强到无法思象。对于英伟达功绩预期来说,Rubin或将推动华尔街大幅上调2026年基本面预测。
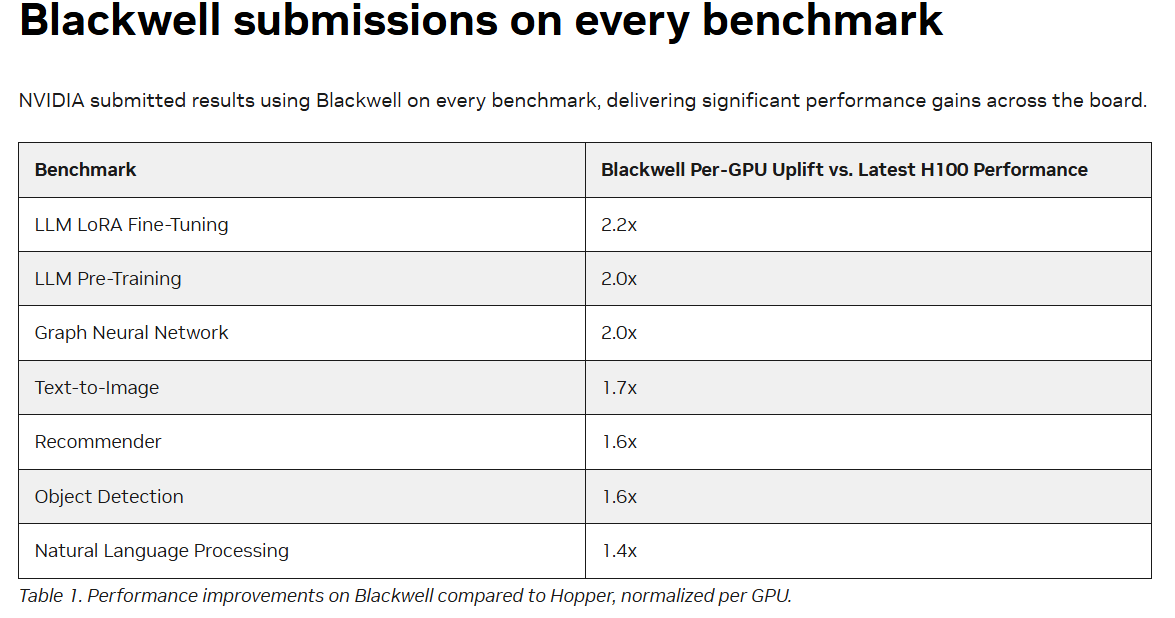
当作基准对标,Blackwell性能照旧比Hopper强劲得多,在MLPerf Training基准测试中,Blackwell在GPT-3预测验任务中每GPU性能比Hopper大幅进步2倍。这意味着在相易数目的GPU下,使用Blackwell不错更快地完成模子测验。对于Llama 2 70B模子的LoRA微调任务,Blackwell每GPU性能比Hopper进步2.2倍,这标明Blackwell在处理特定高负载AI任务时具备更高的恶果。MLPerf Training v4.1 中,图形神经收罗以及Text-to-Image基准测试方面,Blackwell每GPU性能比Hopper差别进步2倍以及1.7倍。
字据知情东说念主士清晰的音讯,以及摩根士丹利调研后的产业链阐明,Rubin架构AI GPU 方案秉承台积电最新3nm 工夫、CPO 封装以及 HBM4;Rubin的芯片尺寸或将是Blackwell的近两倍,Rubin可能包含四个中枢测度芯片,是Blackwell架构的两倍。知情东说念主士显现,3nm Rubin 架构揣度将在2025年下半年参加流片阶段,较英伟达之前预期时期提前半年阁下。
字据面前表裸露的音讯来看,Rubin架构的最大亮点无疑是共同封装光学(CPO)。Hopper与Blackwell互连工夫更多仍依赖转换之后的 NVLink 以及芯片互连工夫,而不是获胜通过光学形势进行数据传输。
Rubin梗概率是各人首个取舍CPO+硅晶圆先进封装的数据中心级别AI芯片,CPO所带来的数据传输恶果以及能耗恶果,或将比拟于NVLink 呈现出指数级飞跃。在CPO封装体系中,光学元器件(如激光器、光调制器、光纤和光探伤器)获胜与中枢测度芯片(如GPU或CPU)封装在一都,而不是将光学器件单独放弃在芯片外部,这些光学元件的作用是传递光信号,替代传统的电信号传输形势,进行芯片间数据的高速传输,大幅减少电子数据从芯片到光学接口之间的信号损耗,指数级提高数据概述量的同期还能大幅镌汰功耗。
通过光信号的高速传输,CPO能提供比传统电信号传输更高的数据带宽,这对于东说念主工智能、大数据以及高性能测度(HPC)诓骗中,尤其是在需要大范围并行测度时至关发愤。因此CPO封装被合计是英伟达Rubin架构AI GPU的中枢亮点,它将为下一代AI和高性能测度提供极高的带宽、低蔓延和大幅进步的能效。在业内东说念主士看来,由于CPO工夫能够更大程度管理数据传输速率和功耗问题,它的诓骗将进一步推动英伟达在数据中心AI芯片市集的越过地位。
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
背负剪辑:郭明煜 开云kaiyun.com


